Escola ISIS de Radicalização Religiosa: Uma Análise com NLP
Nesse post nós iremos fazer uma simples (e rápida) análise do dataset “ISIS Religious Texts v1”, que pode ser encontrado https://www.kaggle.com/fifthtribe/isis-religious-texts. Essa base de dados contém textos de duas revistas do ISIS, estas sendo a “Dabiq” e a “Rumyiah”, que são (ou eram?) usadas para propaganda política e recrutamento de novos membros para o grupo terrorista.
Primeiro começamos carregando as bibliotecas essenciais para a tarefa, com atenção à Rlang, que nos será bem util. Você pode conferir melhor suas funcionalidades nessa publicação https://www.tidyverse.org/blog/2018/03/rlang-0.2.0/, feita pelo time de desenvolvedores do Tidyverse.
library(tidyverse) # É uma meta-biblioteca, isto é, uma bib. que contém outras bibliotecas.
library(tm) # Text mining no geral, faz de tudo um pouco.
library(topicmodels) # Para criar o modelo LDA.
library(tidytext) # Ferramentas de tidy NLP.
library(SnowballC) # Para o stemming!
library(magrittr) # NEW TOOLS!
library(rlang)
library(forcats)Então vamos carregar os dados na memória, usando o {readr}, que já vem incluso na meta-biblioteca {tidyverse}. Contudo, para evitar problemas de compatibilidade de caracteres, visto que podemos ter texto em árabe, já me antecipo e altero o https://en.wikipedia.org/wiki/Character_encoding da coluna que contém o texto para UTF-8, que é o ideal para as bibliotecas de análise de texto que serão usadas (especialmente a {tm}). Em diversas situações, podem ocorrer erros durante a análise devido ao texto estar no encoding errado, a alteração deste – embora tenha um motivo claro, e preventivo, neste dataset – pode ser útil em outros contextos também.
dataset = readr::read_csv('../../data/ISIS Religious Texts v1.csv') # Carrega os dados
dataset$Quote = iconv(dataset$Quote, "ASCII", "UTF-8", sub="byte") # Altera o encoding
head(dataset)## # A tibble: 6 x 8
## Magazine Issue Date Type Source Quote Purpose `Article Name`
## <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Dabiq 1 Jun-14 Jiha… Abu Mus… The spark has … Support First Page
## 2 Dabiq 1 Jun-14 Hadi… Sahih M… <93>The Hour w… Support Introduction
## 3 Dabiq 1 Jun-14 Jiha… Abu Mus… <93>The spark … Support Introduction
## 4 Dabiq 1 Jun-14 Jiha… Abu Bak… <93>O Muslims … Support Khilafah Declared
## 5 Dabiq 1 Jun-14 Jiha… Abu Bak… <93>O Ummah of… Support The World has Di…
## 6 Dabiq 1 Jun-14 Jiha… Abu Bak… <93>Therefore,… Support A Call to HijrahAo observar o dataset vemos que ele possui 8 colunas e aproximadamente 2.700 linhas. Informações como data (2014-2016), revista, tipo e propósito são insumos valiosos, e não serão usadas aqui para mantermos esta publicação em um tamanho restrito. Uma ideia que não será abordada nessa publicação é observarmos se há alteração do discurso conforme a situação política do ISIS se agrava, será que o tom passou a ser mais messiânico? Não sei, fica o exercicio ao leitor.
Enfim, passemos ao código…
Como sempre começamos com uma função, dessa vez crio uma chamada cleaner_impurities, o que ela faz é simples. Ela passa o texto pela função stringr::str_replace_all(), que substitui um elemento expresso por meio de expressão regular, por outro. No código abaixo, entra texto, que é passado pela função anteriormente descrita, e então retornado sem pontuação, com um espaço no lugar.
cleaner_impurities = function(text){
text %>%
stringr::str_replace_all("[[:punct:]]", " ")
text
}Mas calma… Você, pessoa bonita e atenta, poderia me chamar atenção ao fato de que existe a função tm::map(removePunctuation), que ao passarmos no https://en.wikipedia.org/wiki/Text_corpus atinge o mesmo objetivo. Concordo, mas estava afim de brincar com o rlang, e também, a função também dá uma utilidade às https://alphabetsigma.netlify.app/2020/03/17/introducao-as-expressoes-regulares/.
treat = function(data, texto_col= Quote){
data %>%
mutate({{ texto_col }} := cleaner_impurities({{ texto_col }})) %>%
pull({{ texto_col }}) -> data_res
data_res
}A sintaxe da função acima pode ser um pouco nova para alguns, os operadores {{ }} (lê-se Curly-Curly) e := nos permitem utilizarmos os nomes das colunas dos dataframes como argumentos, sem precisarmos recorrer a construções de código obscuras, como é possível ver nesta https://www.brodrigues.co/blog/2019-06-20-tidy_eval_saga/.
Mas, o que essa função faz é bem simples. A função aceita dois argumentos, data e texto_col, a primeira corresponde ao data.frame/tibble que contém os dados a serem tratados, a última corresponde ao nome da coluna qual está o texto desejado. Altera a coluna ‘Quote’, passando-a pela função cleaner_impurities, e então retorna ela como um vetor.
Preste atenção ao fato de que a informação do nome da coluna não deve ser inserida como uma 'string', e sim como se fosse um objeto, https://stackoverflow.com/questions/61377657/tidy-evaluation-not-working-with-mutate-and-stringr.
topTerms = function(text, n_topics=3){
text %>%
SnowballC::wordStem(language= 'english') %>%
tm::VectorSource() %>% # Interpreta cada vetor como um documento.
tm::Corpus() %>% # Cria um corpus com os documentos
tm::tm_map(tolower) %>% # Transforma todos os documentos em letras minusculas
tm::tm_map(removePunctuation) %>%
tm::tm_map(removeNumbers) %>% # Remove os números
tm::tm_map(removeWords, stopwords('english')) %>% # Remove palavras frequentes e que são vazias de significado (the, it, as, etc.)
tm::DocumentTermMatrix() -> DTM # Transforma em uma Document Term Matrix.
indices_unicos <- unique(DTM$i) # index de cada valor único.
DTM <- DTM[indices_unicos, ] # pega um subset desses indexs
topterms <- topicmodels::LDA(DTM, k = n_topics) %>% #Roda o LDA com 3 tópicos
tidytext::tidy(matrix= 'beta') %>% # Transforma o resultado do modelo em um objeto 'tidy', manipulável.
group_by(topic) %>%
top_n(20, beta) %>% # Seleciona os 15 maiores betas.
ungroup %>%
arrange(topic, -beta)
topterms # Retorna.
}
res = dataset %>%
treat() %>%
topTerms()
res## # A tibble: 60 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 allah 0.0468
## 2 1 will 0.0359
## 3 1 said 0.0184
## 4 1 people 0.0109
## 5 1 indeed 0.0108
## 6 1 ibn 0.00961
## 7 1 messenger 0.00770
## 8 1 one 0.00765
## 9 1 say 0.00692
## 10 1 upon 0.00656
## # … with 50 more rowsO trecho acima é bem auto-explicativo, até mesmo devido aos comentários no código. Informações extras podem ser encontradas na documentação das funções.
Vamos plotar as informações que conseguimos, assim é possível visualizarmos melhor o resultado.
plt = res %>% # take the top terms
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
labs(x = NULL, y = "Beta") +
coord_flip()
plt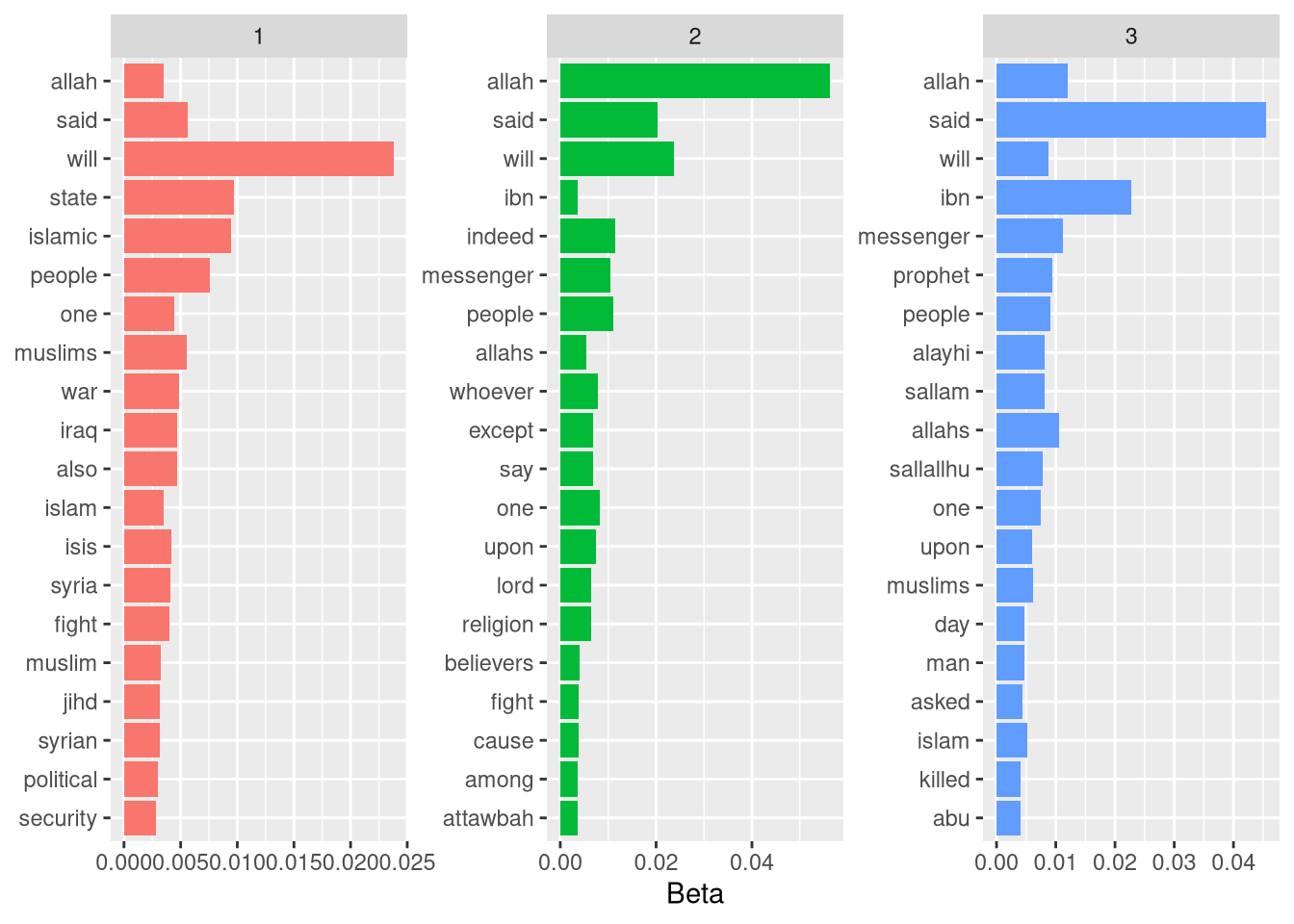
Como esperado, temos quatro grupos, porém, ainda temos muita poluição nos dados. Irei adicionar alguns passos adicionais, e tentaremos ter um resultado mais limpo.
cleaned_docs = function(data){
data %>%
pull({{ Quote }}) %>%
cleaner_impurities %>%
VectorSource() %>%
Corpus() %>%
DocumentTermMatrix() %>%
tidy() %>%
anti_join(stop_words, by = c('term'= 'word')) %>%
group_by(document) %>%
mutate(terms = toString(rep(term, count))) %>%
select(document,terms) %>%
unique()
}
final = topTerms(res) %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
labs(x = NULL, y = "Beta") +
coord_flip()## Warning in tm_map.SimpleCorpus(., tolower): transformation drops documents## Warning in tm_map.SimpleCorpus(., removePunctuation): transformation drops
## documents## Warning in tm_map.SimpleCorpus(., removeNumbers): transformation drops documents## Warning in tm_map.SimpleCorpus(., removeWords, stopwords("english")):
## transformation drops documentsfinal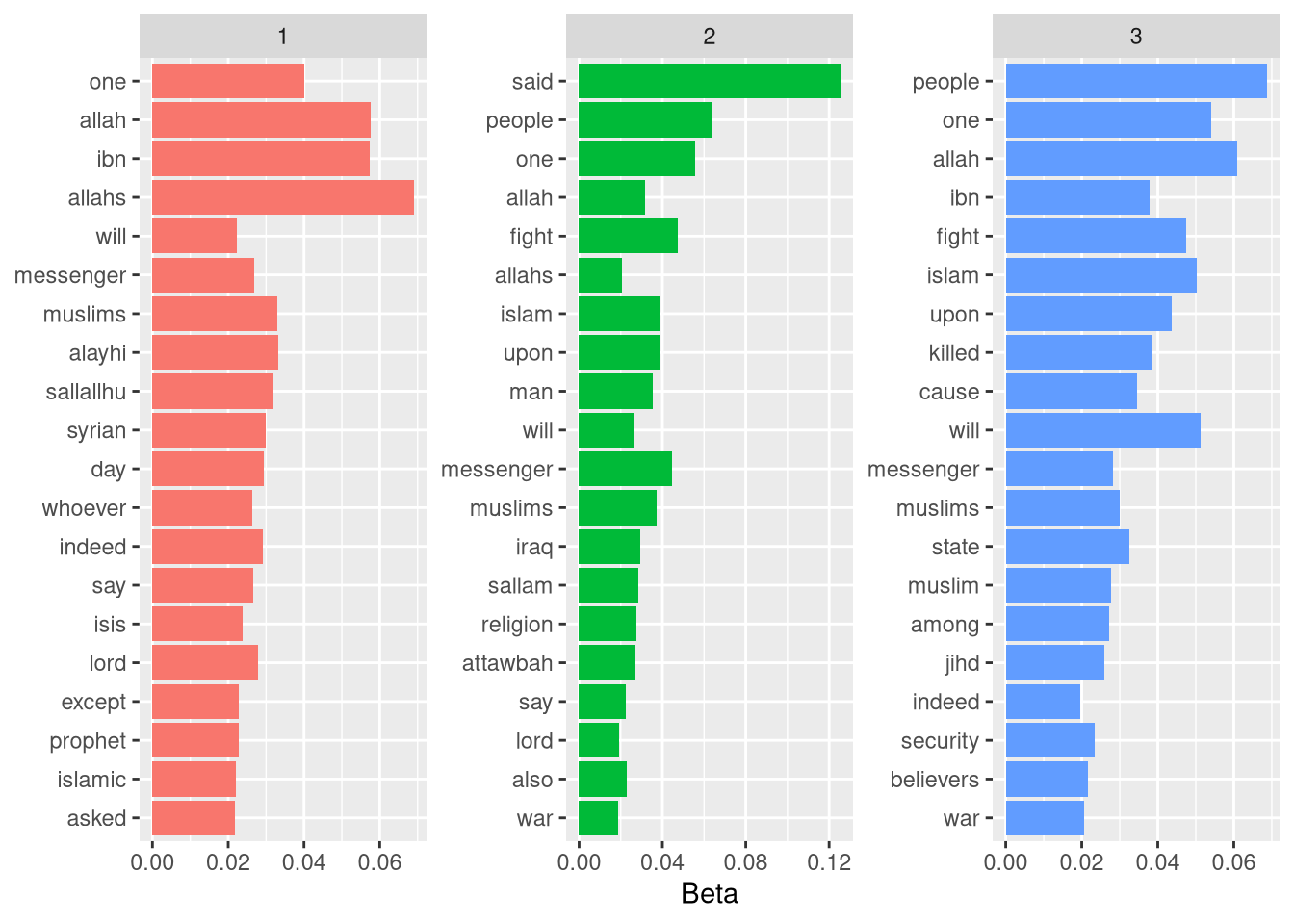
Ok, temos algo melhor. Observando os gráficos na ordem, podemos ter ideia do que cada um dos 4 tópicos abordam, porém não temos nenhuma surpresa advinda deste dataset. Todos nós temos nossos conhecimentos de grupos terroristas, sabemos muito bem como o discurso funciona, devido ao nosso extenso aprendizado com Call of Duty e filmes americanos.
No terceiro, as mensagens tem relação mais intima com assuntos estritamente religiosos. Palavras como Allah, messenger, prophet são de cunho religioso, o que indica que provavelmente esses textos estariam classificados como “Quran”, no dataset. Também mostra que é possível traçar uma distinção entre textos que tratam exclusivamente de religião, é possível acreditar que, por serem textos utilizados por grupos terroristas, estejam relacionados a uma suposta glória da causa.
Em segundo lugar, temos, também, uma infinidade de termos religiosos. Atenção nas palavras people, security, syrian, isis, iraq, jihd (jihad). Por esses termos, podemos imaginar que aqui o tema deixa de ser estritamente a religião, e passa a ser as motivações religiosas que são usadas como desculpa para o fazer a guerra, com especial foco à Síria.
Na primeira coluna, temos palavras importantes, dando destaque à attawbah, esta é a nona Surata do Alcorão, e trata de reparação e trata do balanço e dos problemas da harmonia e da guerra. O grupo de documentos parece ter relação com o sacrificio necessário pela guerra.
Conclusão
No fim, concluo que talvez usar o LDA nesse grupo de documentos não tenha sido a melhor escolha. Voltarei a este dataset no futuro, porém, talvez usando TF-IDF para fazer a análise, espero ter resultados mais satisfatórios. O fato de todos os textos possuirem uma densa carga de discurso religioso pode ter atrapalhado os resultados do modelo, o tamanho dos textos também é um problema, o LDA performa mal em textos curtos. Fica o aprendizado.